"@Grok, is that real?" - Attacking Invisible AI Watermarks Part 1 - Meta PixelSeal
Meta released PixelSeal in December 2025 as part of their VideoSeal repo. It embeds a 256-bit watermark into an image’s latent space, designed to survive compression, re-encoding, and casual tampering. Unlike EXIF metadata, which gets stripped on upload, spatial watermarks persist.
But I wanted to see where it breaks.
Not just theoretical math—I mean actually throwing everything at it. I built a test environment to run automated bypass pipelines against the official pixelseal checkpoint.
What I found: it’s incredibly resilient to passive abuse, but if you actively try to break it, the watermark washes right out.
Here’s what worked, what didn’t, and the methods that actually ripped it out.
The baseline: how we measure “completely broken”
PixelSeal embeds 256 binary bits into the spatial frequency of an image. During detection, the model tries to reconstruct that exact 256-bit string from the pixel data.
If you’re just guessing those bits at random, you’ll naturally hit a 50% Bit Accuracy (BA). To hit the statistically significant $10^{-6}$ False Positive Rate curve (mentioned in Meta’s research paper), you need to recover at least 0.65 BA (~166 correct bits of 256).
My goal was simple: minimize that accuracy.
If I can drag the BA below 0.65, the watermark is effectively dead because the model loses its statistical confidence. For my tests, I pushed for under 0.55 just to be safe. The real challenge, though, was doing this while keeping the PSNR (Peak Signal-to-Noise Ratio) above 30 dB.
It’s easy to break a watermark if you turn the image into a pile of static; the trick is breaking it while keeping the photo looking clean.
# Loading the target
seal = videoseal.load("pixelseal").cuda().eval()
img_tensor = T.ToTensor()(Image.open("sample.jpg")).unsqueeze(0).cuda()
with torch.no_grad():
watermarked_image = seal.embed(img_tensor, is_video=False)["imgs_w"]The baseline control was perfect: BA of 1.000 and an invisible PSNR of 51.9 dB.
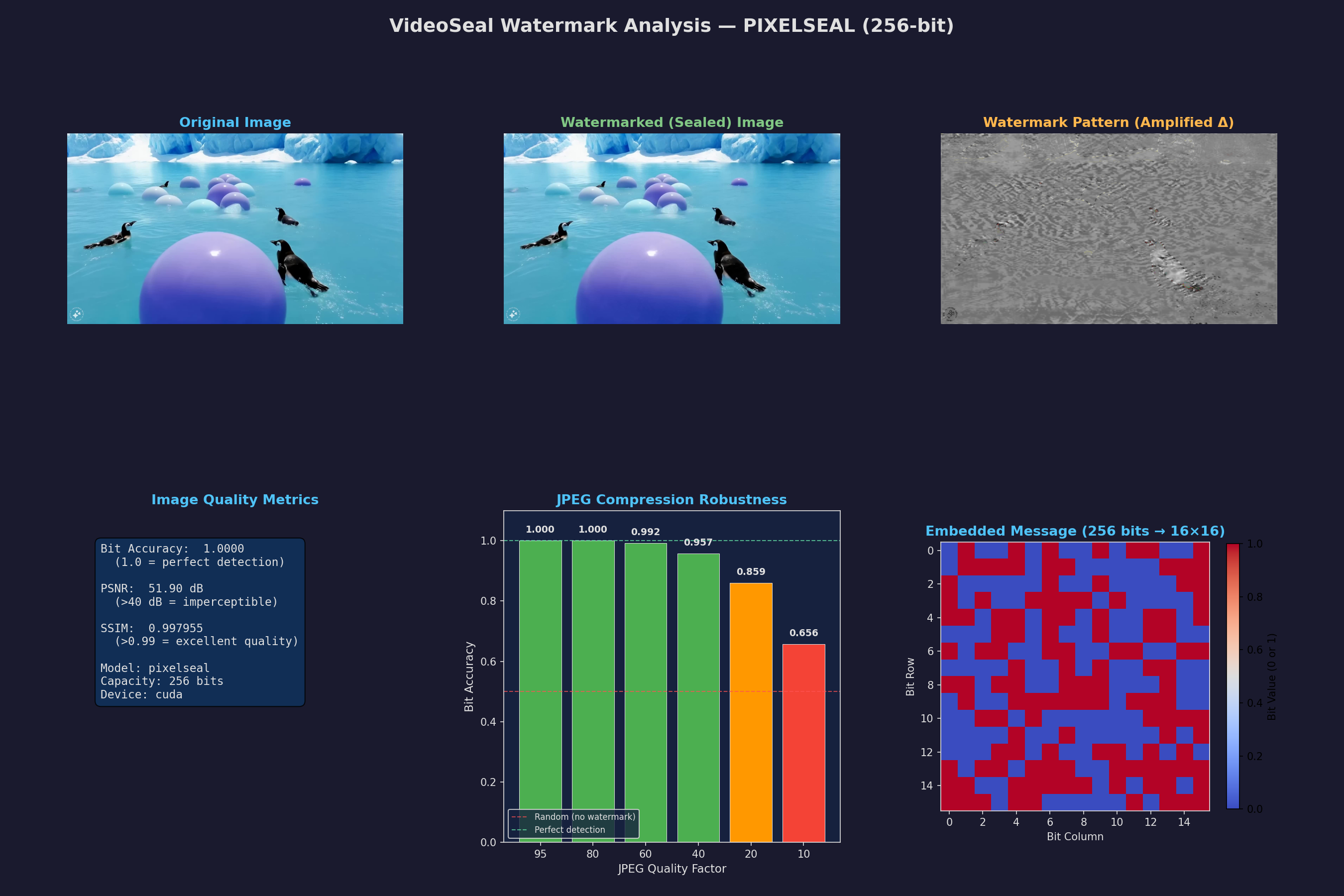
The wall: where PixelSeal is bulletproof
I started with the generic stuff. If someone uploads an AI image to a platform, it gets heavily re-encoded. I simulated this by chaining extreme JPEG compression (Q=50) with Gaussian blurs (kernel 17) and heavy Gaussian noise ($\sigma=0.1$).
It didn’t care at all.
The watermark is encoded in the deep latent structure of the image (based on the Stable Signature architecture), so high-frequency surface noise doesn’t affect it.
So I tried a structural approach. First, I just downscaled the image by 4× (throwing away 75% of the pixels) and used Real-ESRGAN (x4plus) to hallucinate the missing details back.
The result: a total failure. The BA stayed pinned at 0.941.
The problem: ESRGAN is actually too good. It’s designed to preserve the underlying semantics of the input, so it basically just reconstructed the watermark signal with high fidelity. I even tried getting aggressive with it: I smashed the image with a massive Gaussian blur ($\sigma=3.0$) before the downscale/upscale cycle.
Even then, the accuracy only dipped to 0.746. Since that’s still way above my 0.65 threshold, it’s clear: you can’t beat this thing using semantic-preserving super-resolution. The model is just too resilient to those kinds of clean reconstructions.
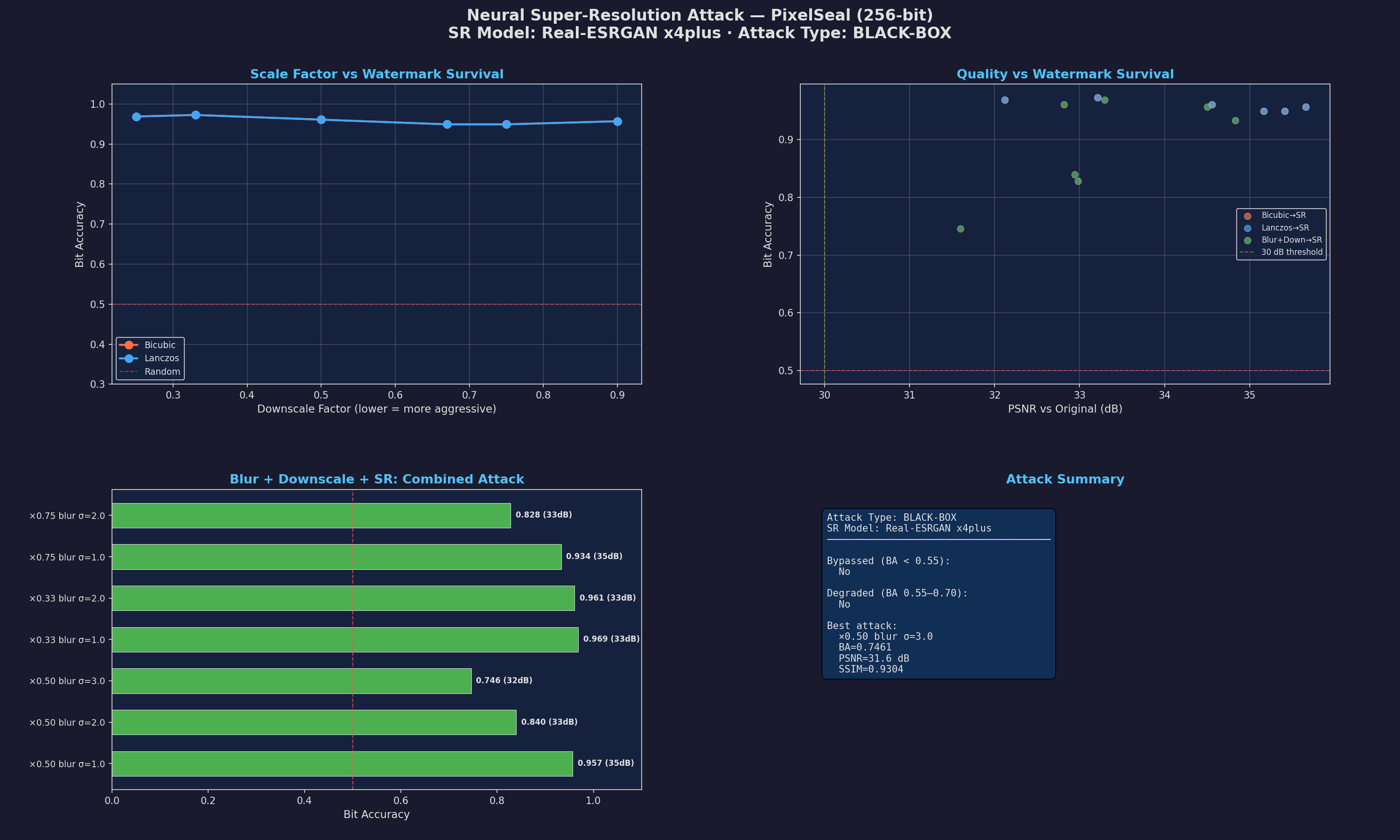
The bypasses: erasing the invisible ink
To actually break this, you have to attack the algorithmic structure itself rather than hoping compression destroys it.
1. Generative scrubbing (Stable Diffusion)
Since ESRGAN was too loyal to the original structure, I figured the move was to force an AI to actually generate something new. I ran the watermarked image through a standard Stable Diffusion (v1.5) img2img pipeline—basically hitting it with a forward-diffusion noise tensor and then denoising the result. The logic here is straightforward: SD doesn’t care about strict mathematical pixel mapping. It reconstructs the missing details using its own generative hallucinations, which in theory should break that underlying watermark structure while keeping the image looking coherent.
out_image = pipe(
prompt="a high quality photograph",
negative_prompt="blurry, distorted, low resolution",
image=watermarked_tensor,
strength=0.15,
guidance_scale=7.5,
).images[0]Result: BA = 0.473, PSNR = 26.4 dB
Even at just 15% strength, the PixelSeal detector totally lost the scent—the math was basically wiped. Now, 26.4 dB PSNR isn’t exactly static and the image is still perfectly recognizable, but you start to see some minor visual shifts. You lose that original pixel-perfect crispness as the diffusion model starts re-drawing textures. It’s a highly effective scrubber, but it’s a trade-off: you’re swapping absolute image fidelity for a guaranteed bypass.

2. The black-box proxy (WmForger)
I needed a bypass that wouldn’t trash the image quality, so I pulled in WmForger (NeurIPS 2025 black-box attack, also mentioned in Meta’s VideoSeal repo). The beauty of this is that it doesn’t even need the PixelSeal weights. It just leans on a surrogate net (ConvNeXt-Tiny) to keep an eye on perceptual quality while using SGD to iterate on the pixels and shove out those latent artifacts.
The results were honestly perfect:
- BA: 0.445
- PSNR: 37.2 dB
In just 50 steps, the bit accuracy cratered to 0.445, which is literally worse than just guessing at random. Meanwhile, the PSNR stayed up at 37.2 dB. Basically, the image looks identical to the human eye, but the watermark is completely nuked.
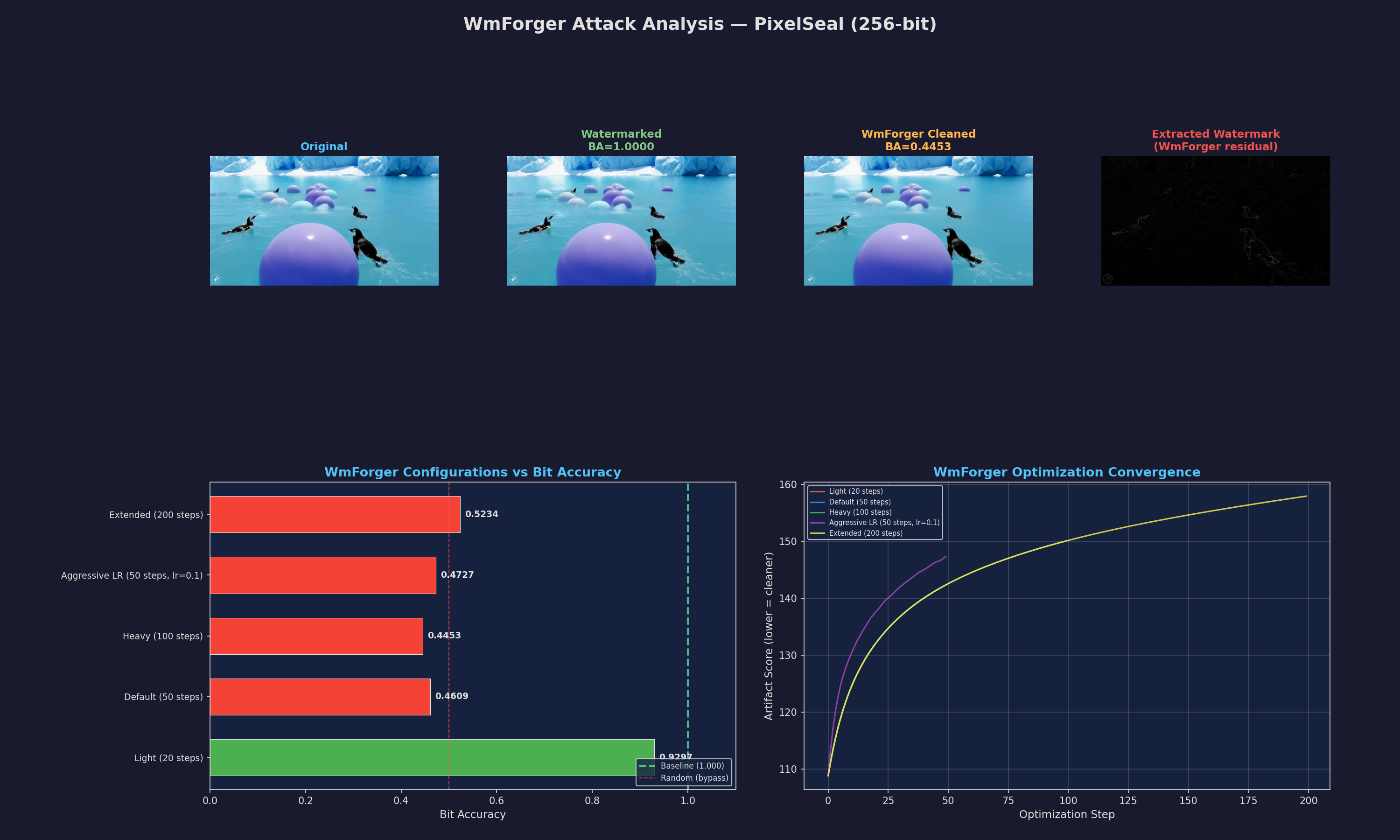
The reality check: content dependency
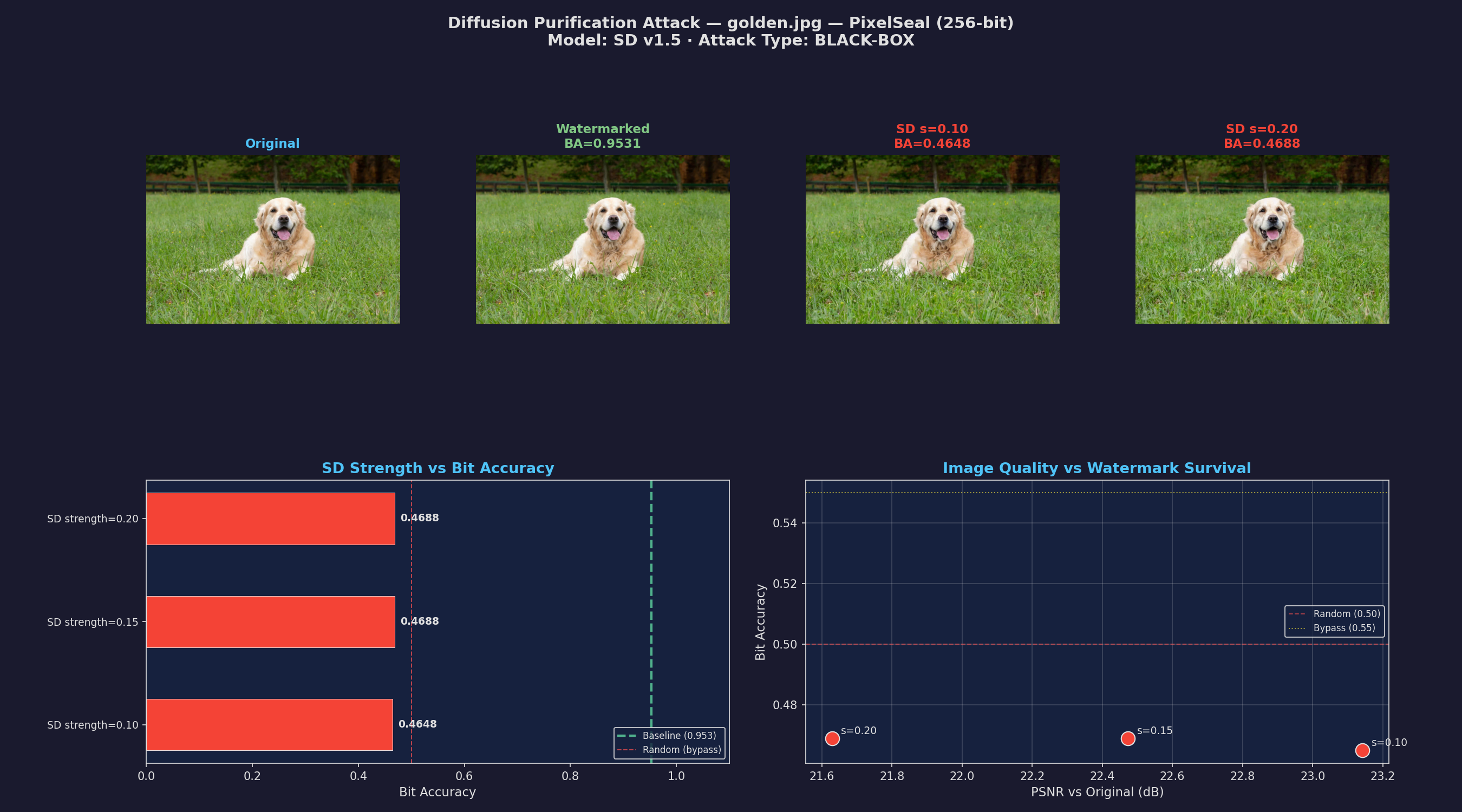
Synthetic AI images and real-world photos have totally different structural topologies. To see how the watermark actually handles natural noise, I ran the whole pipeline again on golden.jpg—a high-frequency portrait of a Golden Retriever with a ton of dense, realistic textures. I added the watermark to the image with PixelSeal.

This is usually where black-box attacks fall apart, and WmForger was no exception. It just couldn’t keep up. I even tried scaling the optimization loop to 200 steps in my test environment to see if I could force it.
Even with 4× the steps, ConvNeXt-Tiny couldn’t map the spatial signature. The mathematical topology of those realistic textures basically hijacked the optimization gradients. The surrogate model got confused and just stopped trying to optimize the watermark out entirely.
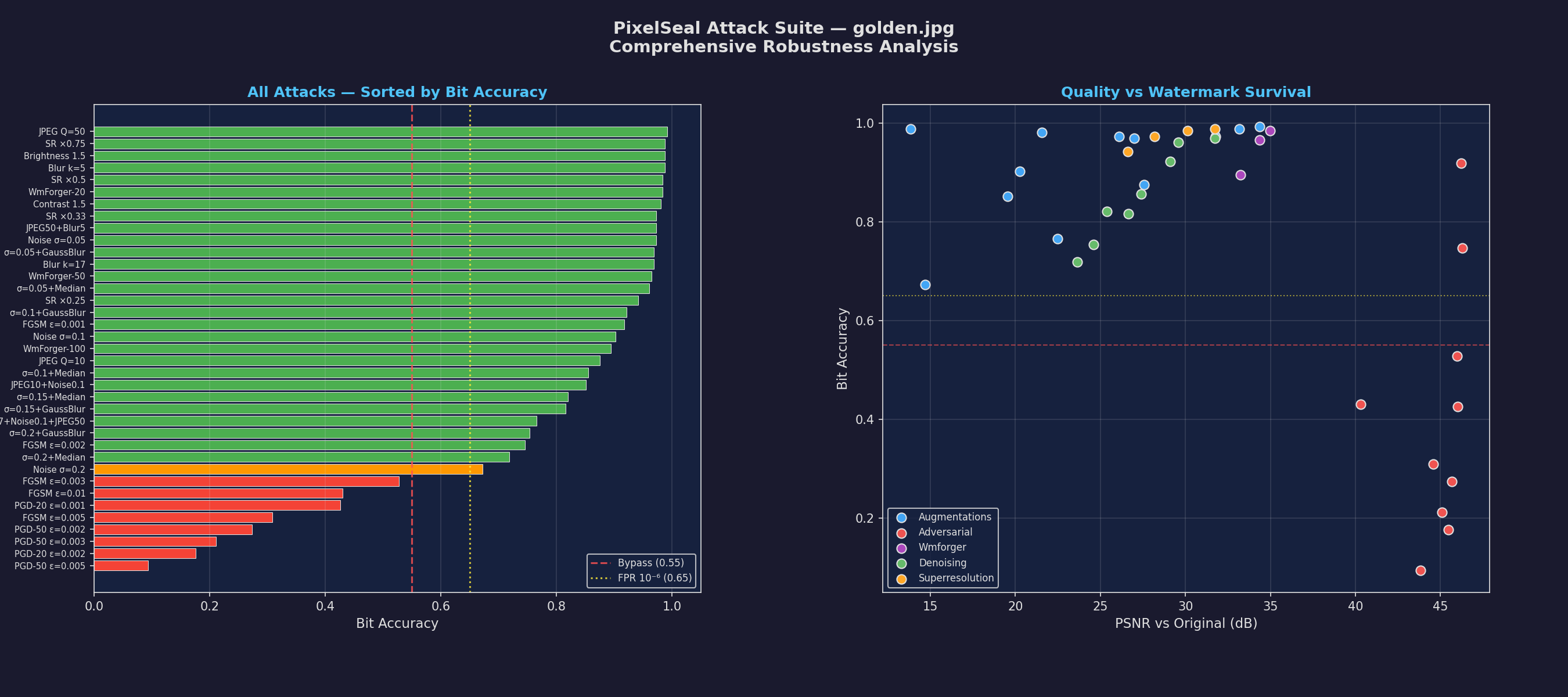
The universal fix: Stable Diffusion
When proxy iteration fails, you either need white-box access or a universal hallucination engine. Since I had white-box access, I ran a PGD (Projected Gradient Descent) attack. It’s a multi-step adversarial move that computes gradients directly through the PixelSeal detector.
Basically, at every step, PGD nudges each pixel just enough to maximize the bit prediction errors, then clips the change to keep it imperceptible ($\epsilon=0.005$).
The results were wild: across 50 iterations, PGD dragged that Golden Retriever image’s Bit Accuracy down to 0.0938—near total destruction—all while keeping the PSNR above 40 dB. Visually, there’s no way you could tell the image was even touched.
But what if you don’t have the weights?
Stable Diffusion is still the best bet. I ran the same golden.jpg through that SD v1.5 img2img pipeline on a T4 GPU:
At just 10% strength, Stable Diffusion successfully scrubbed the watermark. Every single strength tested landed below 0.50—worse than flipping a coin.
Combined with the earlier results on the synthetic image, this shows that SD-based scrubbing works regardless of image content—AI-generated or real photograph, it doesn’t matter.
TL;DR on bypassing: black-box attacks like WmForger are completely at the mercy of the image content. If the textures get too complex, the gradients just stall out. But massive generative pipelines, like Stable Diffusion, act as universal scrubbers. The second a bad actor runs a watermarked image through img2img, that provenance is gone.
I specifically used SD v1.5, the oldest and smallest publicly available diffusion model, to establish the minimum viable attack. If this 2022 model scrubs the watermark on a free Colab T4, newer architectures like SDXL or Flux would only do it more efficiently.
Wrapping up Part 1
So, is Meta’s PixelSeal fundamentally broken? Not exactly. It actually works for what it’s meant to do. If you just want to survive social media compression, basic cropping, or low-effort tampering from casual users, it adds a traceable payload to regular deployments without trashing the image quality.
But against an active adversary? That invisible ink comes right off. It’s the classic trade-off: make the watermark too robust and you ruin the art; make it too subtle and a generative model will just hallucinate right over it.
PixelSeal and VideoSeal are important steps forward for AI safety, but we have to treat them like any other security layer. They aren’t unbreakable vaults; they’re deterrents. They only raise the cost of an attack.
References
- VideoSeal repo: facebookresearch/videoseal
- WmForger: arXiv:2510.20468